ProcessQueue and Producer/Consumer Pattern
It explores the utilization of multiprocessing with queues in Python, highlighting its integration with the producer-consumer pattern.

Figure: To memorize the two years I spent in TU-Berlin.
Introduction
One of the most intriguing things about software engineering is multithreading and multiprocessing. Due to Global Interrupt Lock (GIL), running a program with multithreading differs hugely from multiprocessing in Python. Please see this article for more information about multithreading and multiprocessing. The rule of thumb is that if a program is CPU-bound, go with multiprocessing. If a program is IO-bound, go with multithreading. But what if a program is both CPU-bound and IO-bound simultaneously? E.g., a program needs to read a huge file on a remote server, process it heavily and write the result back to a remote server. Reading and writing to a file in a remote server is considered IO-bound while processing the content of a file is regarded as CPU-bound. Thus, the best approach here is to use multiprocessing and multithreading at the same time. I.e., employing multithreading when reading/writing from/to a remote server and using multiprocessing to process the data.
In addition to multiprocessing, the Producer-Consumer pattern can further decrease a program’s running time. The basic idea of the Producer-Consumer pattern is depicted below. Producer threads/processes prepare data and push data into a queue, while Consumer threads/processes fetch data out of the queue and work on it simultaneously.
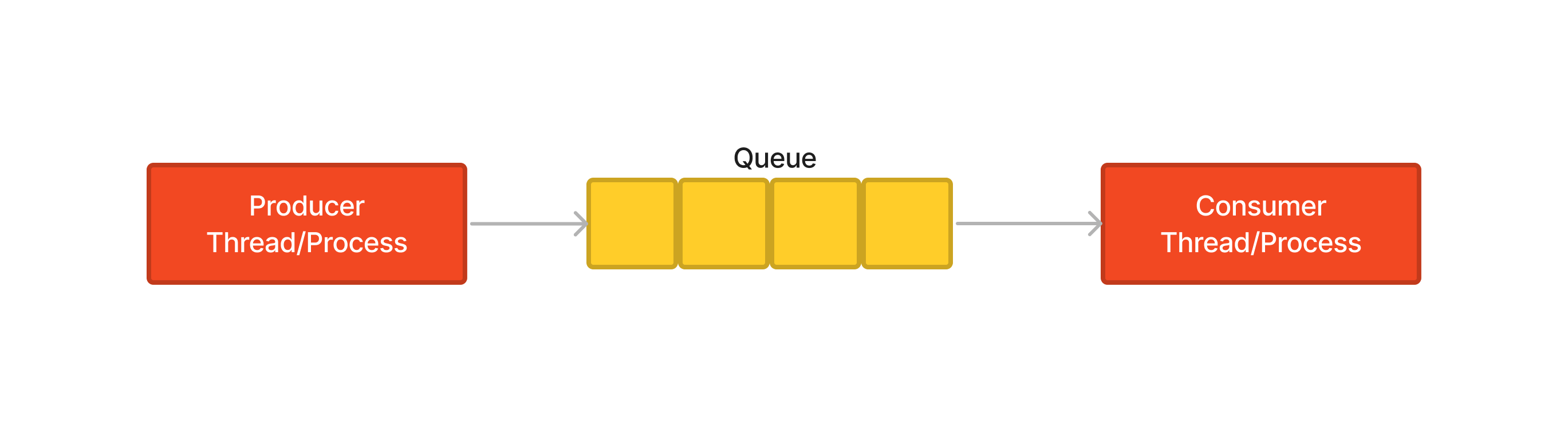
Figure: Graphical illustration of the Producer-Consumer pattern.
In this post, I will implement a generic ProcessQueue class which incorporates the
Producer-Consumer pattern so that users can enjoy the power of the pattern without
worrying about the implementation detail.
Naive Implementation of ProcessQueue
Construction
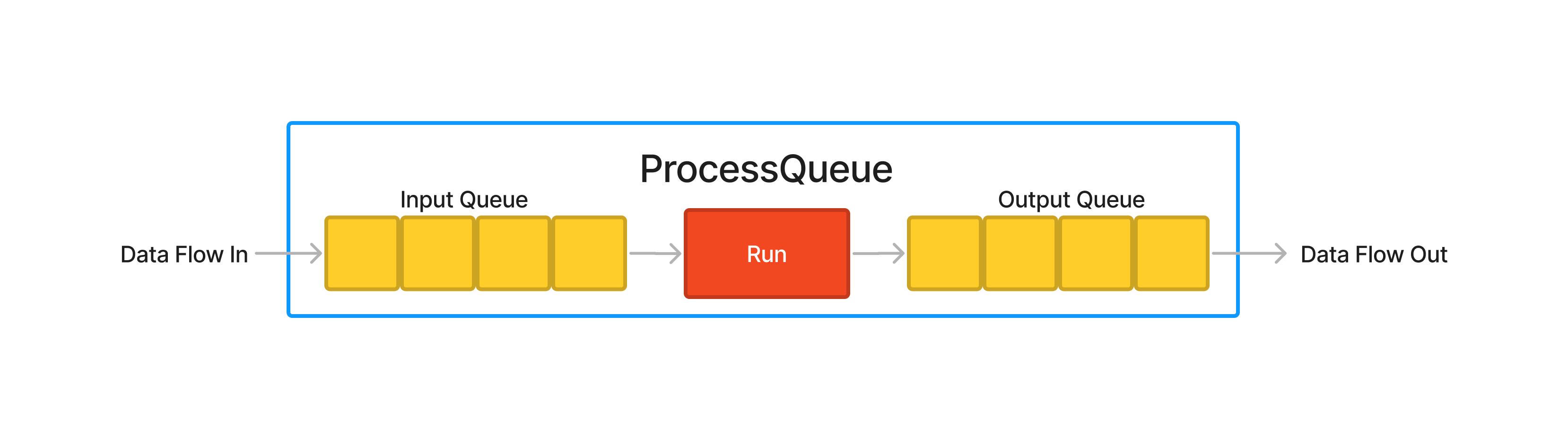
Figure: Graphical illustration of ProcessQueue.
The first naive implementation of ProcessQueue() is presented below:
class EndOfQueue:
pass
class ProcessQueue(multiprocessing.Process):
"""Inherit from multiprocessing.Process and overload run()."""
def __init__(self, in_queue, out_queue, fn: Callable):
super().__init__()
self.fn = fn
self.in_queue = in_queue
self.out_queue = out_queue
def run(self):
while True:
# block till queue is not empty
data = self.in_queue.get()
if isinstance(data, EndOfQueue):
break
print(f"ProcessQueue starts processing {data}.")
result = self.fn(data)
print(f"ProcessQueue finishes processing {data}.")
self.out_queue.put(result) # Put the result into out_queue.
The ProcessQueue() inherits from multiprocessing.Process and overloads run()
method. In run(), it first tries to get data from in_queue. Note that get() will
block the process if in_queue is empty. It then pops data out of in_queue,
processes it and then pushes result into out_queue. From the perspective of
ProcessQueue(), it does not care what functions or data are sent in. It just runs fn
with whatever is pop out of in_queue and put the result into out_queue so that
ProcessQueue() is generic enough to handle all kinds of situations.
When a process is spawned and started, we need to tell this process when to stop and
terminate itself. There are several ways to achieve Inter-Process Communication (IPC),
such as Pipes, Queues, Semaphores, Socket, and Shared Memory, etc. Here, we choose to
send an indicator EndOfQueue via the input queue to notify the process that it reaches
the end of the data flow and is safe to die.
Usage
Here is one example of how ProcessQueue() is used:
def cal_pow(base, exponent):
x = randint(1, 2) # x = 1 or 2
if x == 1:
tmp = randint(1e6, 1e7)
else:
tmp = randint(1e0, 1e1)
while tmp != 0:
tmp -= 1
return base ** exponent
input_queue = multiprocessing.Manager().Queue(maxsize=20)
output_queue = multiprocessing.Manager().Queue()
NUM_PROCESS = 4
processes = []
# Spawn and start four ProcessQueue with input_queue and output_queue
for _ in range(NUM_PROCESS):
processes.append(
ProcessQueue(
in_queue=input_queue,
out_queue=output_queue,
fn=partial(cal_pow, exponent=2),
)
)
for p in processes:
p.start()
print("Start pushing data")
time.sleep(1)
for i in range(100):
print(f"Pushing {i}")
input_queue.put(i)
# Push indication EndOfQueue().
for _ in range(NUM_PROCESS):
input_queue.put(EndOfQueue())
print("Finish pushing data")
for p in processes:
p.join()
while True:
if not output_queue.empty():
print(f"Pop {output_queue.get()} out")
else:
break
print("Program ends.")
cal_pow(base, exponent)is the target function we want to run multiprocessing. I put a delay mechanism that will randomly loop either a few times or millions of times to mimic that some data requires more processing time than others in the real world.input_queueandoutput_queuemust bemultiprocessing.Queuebut notqueue.Queue. According to the documentation,multiprocessing.Queuereturns a process shared queue implemented using a pipe and a few locks/semaphores, i.e.,multiprocessing.Queueis thread- and process-safe. The size of theinput_queueis determined by how much memory we would like to use and how fast the target function can consume the data.- Next, we spawn and start four
ProcessQueue()withexponent=2. Then, we push data andEndOfQueue()intoinput_queue.join()method is called to block the program until all data in theinput_queuehas been processed. Lastly, we pop the data out ofoutput_queuefor inspection.
The output message below shows everything as expected:
- The data has been processed parallelly by multiple processes. When one process
handles data
1for a long time, other processes have been consuming data in the queue and continuing their life independently. - The data order of the result in the output queue also verifies the program’s
parallelism. Data
9is ahead of data0, and data8464is the last one in the queue as opposed to data9801(99*2).
Start pushing data
Pushing 0
Pushing 1
ProcessQueue starts processing 0.
Pushing 2
ProcessQueue starts processing 1.
Pushing 3
ProcessQueue starts processing 2.
...
ProcessQueue finishes processing 1.
ProcessQueue starts processing 11.
Pushing 32
...
Pushing 99
ProcessQueue starts processing 79.
...
ProcessQueue starts processing 83.
Finish pushing data
ProcessQueue finishes processing 80.
...
ProcessQueue finishes processing 92.
Pop 9 out
Pop 16 out
Pop 25 out
Pop 0 out
...
Pop 9801 out
...
Pop 8464 out
Program ends.
Improved Implementation of ProcessQueue
One downside of the first naive implementation is that it only allows one variable
base to be sent to the target function. In practice, we want to send multiple
variables (base and exponent in the example case) to the target function. Thus, we
need to improve the naive implementation.
Dictionary and Unpack data
We shall keep two things in mind here:
- First, the signature of the user function
cal_powmust not be changed. I don’t know about you. But I have mental block to use a specfic library if I must change my function’s signature. - Second, the implementation needs to be generic so that any parameters can be sent in.
Thus, we need to pack the multiple variables as an dictionary data and unpack it in
ProcessQueue.run().
# Pack variables when pushing data into the input queue.
data = {"base":i+1, "exponent":i-1}
input_queue.put(data)
def run(self):
while True:
data = self.in_queue.get()
if isinstance(data, EndOfQueue):
break
# Unpack data
result = self.fn(**data)
self.out_queue.put(result)
The output message below shows that two parameters are sent into the queue rightly, and the computation result is correct.
Start pushing data
Pushing 0
Pushing 1
ProcessQueue starts processing {'base': 1, 'exponent': -1}.
Pushing 2
ProcessQueue starts processing {'base': 2, 'exponent': 0}.
...
ProcessQueue finishes processing {'base': 100, 'exponent': 98}.
Pop 3 out
...
Pop 1.0 out
Pop 16 out
Pop 1 out
...
Pop 1E196 out
Program ends.
Scalability
When I develop multiprocessing/multithreading programs, I always try to verify the programs’ scalability as early as possible. A program is scalable if it takes less time to run when more CPUs are used. E.g., if 2, 4, or 8 CPUs are used to run a program separately, does it reduce the running time to about one-half, one-fourth, or one-eighth? If so, this program is scalable. If not, then this program is not scalable. I.e., throwing more CPUs at it won’t help to reduce the processing time.
Sometimes I found out that using more CPUs does not help speed up my program, and usually, there are two loopholes. First, the bottleneck is not where I use more CPUs. E.g., when reading and writing a file from/to a remote server, apparently the bottleneck is the throughput of the internet, but not the processing of the data. Second, using the wrong data structures to store the data or overlooking the importance of the CPU caches plays in software engineering. For instance, given two lists storing objects, I need to iterate through the first list and do some algebraic operation for each object in the second list. I once made my program 100 times faster by preloading required information from objects in two lists to two matrices and using matrix vectorization to do the algebraical operation. Thus, it’s always nice to justify the usage of multiprocessing/multithreading before realizing the issues are not meant to be solved by multiprocessing after unnecessarily wasting time on it.
The table below shows the running time of cal_pow() when CPUs increase. It’s not
perfect linear time reduction, but it’s enough to show that our program is scalable.
| Num of CPUs | Running Time (seconds) |
|---|---|
| 1 | 7.5 |
| 2 | 4.7 |
| 4 | 3.2 |
| 8 | 2.3 |
That’s it. I introduced the implementation and usage of the Producer-Consumer pattern with multiprocessing and queue in Python. Before the end of this post, I’d like to discuss a few more details about the start method of multiprocessing.
Fork vs Spawn
In Linux system, the first process is called init, which is the parent or grandparent of all processes on our Linux system, and all child processes are forked by default. Python has three start methods, spawn, fork, and forkserver. A few key differences between fork and spawn are discussed here.
Virtual Address
A Path object file is instantiated in the main process and it is sent into a child
process whose start method is fork. We use Python built-in function
id() to print out the address
in virtual memory.
def show_object_identity(file):
print(f"Child process: ID={os.getpid()}, Object={mp.current_process()}.")
print(f"Child process: id(file)={id(file)}")
if __name__ == "__main__":
mp.set_start_method("fork")
file = Path("test.txt")
print(f"Main process: ID={os.getpid()}, Object={mp.current_process()}.")
print(f"Main process: id(file)={id(file)}")
p1 = mp.Process(target=show_object_identity, args=(file,))
p1.start()
p1.join()
The output message below shows that file has the same virtual address in the main and
child process, which verifies
the description of fork in the documentation.
fork
The parent process uses os.fork() to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process.
Main process: ID=10590, Object=<_MainProcess name='MainProcess' parent=None started>.
Main process: id(file)=140014818399616
Child process: ID=10595, Object=<Process name='Process-1' parent=10590 started>.
Child process: id(file)=140014818399616
Now let’s change the start method to spawn mp.set_start_method("spawn"). It shows that
the address of file in the child process is different to the file’s address in the
main process, which means that the spawn method will create a whole new python
interpreter process with a new virtual address space.
Main process: ID=10618, Object=<_MainProcess name='MainProcess' parent=None started>.
Main process: id(file)=139768830076288
Child process: ID=10624, Object=<Process name='Process-1' parent=10618 started>.
Child process: id(file)=140613474682800
spawn
The parent process starts a fresh python interpreter process. The child process will only inherit those resources necessary to run the process object’s run() method. In particular, unnecessary file descriptors and handles from the parent process will not be inherited.
Global Variables
I would like to know how resources of the parent are inherited by the child in terms of global variables.
fork
The parent process uses os.fork() to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process.
a is instantiated before Process.start() is called while b is instantiated
afterwards.
def show_object_identity():
print(f"Child process: id(a)={id(a)}, a={a}")
print(f"Child process: id(b)={id(b)}, b={b}")
if __name__ == "__main__":
mp.set_start_method("fork")
p1 = mp.Process(target=show_object_identity)
a = 10
print(f"Main process: id(a)={id(a)}, a={a}")
p1.start()
b = 10.0
print(f"Main process: id(b)={id(b)}, b={b}")
p1.join()
The result shows that a is essentially the same as in the main and child processes,
and b is not defined in the child process. Why is that? b is not inherited.
Main process: id(a)=9789280, a=10
Main process: id(b)=139996922467152, b=10.0
Child process: id(a)=9789280, a=10
Process Process-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/usr/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "test.py", line 21, in show_object_identity
print(f"Child process: id(b)={id(b)}, b={b}")
NameError: name 'b' is not defined
More about Global Variables
Let’s look at a bit more complicated example below.
a,b, andcare instantiated beforeProcess.start().- In the child process,
aandcare assigned to a new value. - We print
a,b, andcagain after the child process ends.
def show_object_identity():
a = 5
print(f"Child process: id(a)={id(a)}, a={a}")
print(f"Child process: id(b)={id(b)}, b={b}")
print(f"Child process: id(c)={id(c)}, c={c}")
c = False
if __name__ == "__main__":
mp.set_start_method("fork")
p1 = mp.Process(target=show_object_identity)
a = 10
b = 1.0
c = True
print(f"Main process: id(a)={id(a)}, a={a}")
print(f"Main process: id(b)={id(b)}, b={b}")
print(f"Main process: id(c)={id(c)}, c={c}")
p1.start()
p1.join()
print("After child process ends.")
print(f"Main process: id(a)={id(a)}, a={a}")
print(f"Main process: id(b)={id(b)}, b={b}")
print(f"Main process: id(c)={id(c)}, c={c}")
Something interesting happens here.
- First,
ain the main process andain the child process are different objects. - Second,
bin the main process andbin the child process are the same objects. It illustrates the copy-on-write mechanism on Linux system. - Third, an error
local variable 'c' referenced before assignmentoccurs becausecis assigned to a new value in the child process. That means Python will automatically recognise it as a different object as in the main process. - Lastly, after the child process ends, objects
a,b, andcare printed again. It shows that they stay exactly the same in the main process. Essentially it means that resources inherited by the child process can only be read but not written from the perspective of the parent process.
Main process: id(a)=9789280, a=10
Main process: id(b)=139705965609808, b=1.0
Main process: id(c)=9476448, c=True
Child process: id(a)=9789120, a=5
Child process: id(b)=139705965609808, b=1.0
Process Process-1:
Traceback (most recent call last):
File "/usr/lib/python3.8/multiprocessing/process.py", line 315, in _bootstrap
self.run()
File "/usr/lib/python3.8/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "test.py", line 23, in show_object_identity
print(f"Child process: id(c)={id(c)}, c={c}")
UnboundLocalError: local variable 'c' referenced before assignment
After child process ends.
Main process: id(a)=9789280, a=10
Main process: id(b)=139705965609808, b=1.0
Main process: id(c)=9476448, c=True
Shared Memory vs Passed Resource vs Global Resource
In the documentation, it says:
On Unix using the fork start method, a child process can make use of a shared resource created in a parent process using a global resource. However, it is better to pass the object as an argument to the constructor for the child process.
We now take a deeper view of how passing resource to child processes differs from sharing global resource with child processes. Consider the following example:
show_object_identity()takes two parameters,pass_bis a built-in integer object andshared_cis amultiprocessing.Valueobject with boolean type. We first assign a new value toglobal_a(actually it’s an instantiation), and then print the identities of all three objects,global_a,pass_b, andshared_c. Then we assign new values topass_b, andshared_c, and print the identities again.- Three objects
global_a,pass_b, andshared_care all instantiated beforemultiprocessing.start().
def show_object_identity(pass_b, shared_c):
global_a = 5
print(f"Child process: id(global_a)={id(global_a)}, global_a={global_a}")
print(f"Child process: id(pass_b)={id(pass_b)}, pass_b={pass_b}")
print(f"Child process: id(shared_c)={id(shared_c)}, shared_c={shared_c}")
pass_b = 1
shared_c.value = False
print("After Assignment...")
print(f"Child process: id(global_a)={id(global_a)}, global_a={global_a}")
print(f"Child process: id(pass_b)={id(pass_b)}, pass_b={pass_b}")
print(f"Child process: id(shared_c)={id(shared_c)}, shared_c={shared_c}")
if __name__ == "__main__":
mp.set_start_method("fork")
global_a = 10
pass_b = 1.0
shared_c = mp.Value(c_bool, True)
print(f"Main process: id(global_a)={id(global_a)}, global_a={global_a}")
print(f"Main process: id(pass_b)={id(pass_b)}, pass_b={pass_b}")
print(f"Main process: id(shared_c)={id(shared_c)}, shared_c={shared_c}")
p1 = mp.Process(target=show_object_identity, args=(pass_b, shared_c))
p1.start()
p1.join()
print("After child process ends.")
print(f"Main process: id(global_a)={id(global_a)}, global_a={global_a}")
print(f"Main process: id(pass_b)={id(pass_b)}, pass_b={pass_b}")
print(f"Main process: id(shared_c)={id(shared_c)}, shared_c={shared_c}")
Let’s look at all the objects one by one:
global_a:global_adoesn’t do something crazy here. Its behaviour has been discussed in the previous example.pass_b:pass_bdoes surprise me a little. Its address has stayed the same in the child process before the assignment, but after it is assigned to a new value (which is integer one), its value and address change. This phenomenon again demonstrates the copy-on-write mechanism on Linux system.shared_c:shared_chas been the most stable one here. Its address has stayed the same throughout the lifetime of the program, and its value has been faithfully changed both in the child and parent processes.
Main process: id(global_a)=9789280, global_a=10
Main process: id(pass_b)=140586864100176, pass_b=1.0
Main process: id(shared_c)=140586502381280, shared_c=<Synchronized wrapper for c_bool(True)>
Child process: id(global_a)=9789120, global_a=5
Child process: id(pass_b)=140586864100176, pass_b=1.0
Child process: id(shared_c)=140586502381280, shared_c=<Synchronized wrapper for c_bool(True)>
After Assignment...
Child process: id(global_a)=9789120, global_a=5
Child process: id(pass_b)=9788992, pass_b=1
Child process: id(shared_c)=140586502381280, shared_c=<Synchronized wrapper for c_bool(False)>
After child process ends.
Main process: id(global_a)=9789280, global_a=10
Main process: id(pass_b)=140586864100176, pass_b=1.0
Main process: id(shared_c)=140586502381280, shared_c=<Synchronized wrapper for c_bool(False)>
The moral in this example:
- Try to avoid sharing global resources. Sharing global resources with child processes and passing resources to child processes do not differ too much. However, the code is easier to maintain when passing resources to child processes (think about the function parameters).
- If a child process needs to change the state of resources, the Inter-Process
Communication should be used. Otherwise, the behaviour of
pass_bis expected.
Picklability
Lastly, I’d like to talk about picklability. As a geospatial software engineer, I will
use the DatasetReader object from the
geospatial package rasterio as an example
to demonstrate how to handle an unpickable object in a multiprocessing program.
default_profile() creates an artificial profile of a raster. read_dataset() prints
the virtual memory address of DatasetReader and reads the content of
DatasetReader with the given Window. write_dataset basically does the same thing
except for writing behaviour.
def default_profile():
return {
"count": 1,
"driver": "GTiff",
"dtype": "float32",
"nodata": -999999.0,
"width": 100,
"height": 100,
"transform": rasterio.Affine(1.0, 0.0, 0.0, 0.0, 1.0, 0.0),
"tiled": True,
"interleave": "band",
"compress": "lzw",
"blockxsize": 256,
"blockysize": 256,
}
def read_dataset(dataset_read: DatasetReader, window: Window):
print(f"Read child process: ID={os.getpid()}, Object={multiprocessing.current_process()}.")
print(f"Read child process: id(dataset_read)={id(dataset_read)}")
dataset_read.read(window=window)
print("Read dataset successfully.")
print(f"Read child process: id(dataset_read)={id(dataset_read)}")
def write_dataset(dataset_write: DatasetWriter, pixels: np.ndarray, window: Window):
print(f"Write child process: ID={os.getpid()}, Object={multiprocessing.current_process()}.")
print(f"Write child process: id(dataset_write)={id(dataset_write)}")
dataset_write.write(pixels, window=window)
print("Write dataset successfully.")
print(f"Write child process: id(dataset_write)={id(dataset_write)}")
window, pixels, default_profile, dataset_write, and dataset_read are
instantiated before multiprocessing.start() so that they can be passed to and
inherited by the child processes, p1 and p2. Lastly, we can reread test_write.tiff
to verify pixels are written correctly.
if __name__ == "__main__":
multiprocessing.set_start_method("fork")
window = rasterio.windows.Window(col_off=0, row_off=0, width=100, height=100)
pixels = np.ones((1, 20, 20))*100
default_profile = default_profile()
with rasterio.open(Path("test_write.tiff"), mode="w", **default_profile) as dataset_write:
with rasterio.open(Path("test_read.tiff"), mode="r") as dataset_read:
print(f"Main process: ID={os.getpid()}. id(dataset_write)={id(dataset_write)}. id(dataset_read)={id(dataset_read)}")
p1 = multiprocessing.Process(target=write_dataset, args=(dataset_write, pixels, window))
p2 = multiprocessing.Process(target=read_dataset, args=(dataset_read, window))
p1.start()
p2.start()
p1.join()
p2.join()
with rasterio.open(Path("test_write.tiff"), mode="r") as ds:
print("The test_write.tiff raster: ")
print(ds.read())
The output shows something I didn’t expect.
Main process: ID=14613. id(dataset_write)=139954542159616. id(dataset_read)=139954534240320
Write child process: ID=14619, Object=<Process name='Process-1' parent=14613 started>.
Write child process: id(dataset_write)=139954542159616
Read child process: ID=14620, Object=<Process name='Process-2' parent=14613 started>.
Write dataset successfully.
Write child process: id(dataset_write)=139954542159616
Read child process: id(dataset_read)=139954534240320
Read dataset successfully.
Read child process: id(dataset_read)=139954534240320
The test_write.tiff raster:
[[[-999999. -999999. -999999. ... -999999. -999999. -999999.]
[-999999. -999999. -999999. ... -999999. -999999. -999999.]]]
- Out of expectation, both processes finish without error, which surprisingly contradicts this issue.
rasterio datasets can’t be pickled and can’t be shared between processes or threads. The work around is to distribute dataset identifiers (paths or URIs) and then open them in new threads.
dataset_read’s virtual address stays the same in parent and child process.dataset_write’s virtual address also remains the same in parent and child process even though there is writing behaviour in the child process. My explanation is thatwrite_dataset()doesn’t actually change the objectdataset_writeitself.- In the end, the pixels value
-999999intest_write.tiffis not written successfully by child process, which implies we must writeDatasetWriterin the main process.
Finally (it really is the last word of this post), let’s see what happens when changing
the start method to spawn (mp.set_start_method("spawn")). Unsurprisingly, the
error occurs because rasterio
dataset is not picklable.
Main process: ID=16335. id(dataset_write)=140150660764576. id(dataset_read)=140150660745792
Traceback (most recent call last):
File "test.py", line 67, in <module>
p1.start()
File "/usr/lib/python3.8/multiprocessing/process.py", line 121, in start
self._popen = self._Popen(self)
File "/usr/lib/python3.8/multiprocessing/context.py", line 224, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/usr/lib/python3.8/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/usr/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/usr/lib/python3.8/multiprocessing/popen_fork.py", line 19, in __init__
self._launch(process_obj)
File "/usr/lib/python3.8/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/usr/lib/python3.8/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
File "stringsource", line 2, in rasterio._io.DatasetWriterBase.__reduce_cython__
TypeError: self._hds cannot be converted to a Python object for pickling
Conclusion
I implement a generic class ProcessQueue, which incorporates the Producer-Consumer
pattern internally and dive deep into the start method of multiprocessing package to
show the best approach between shared memory, inheriting global resource and passing
resource to processes, and discuss the effect of an object’s picklability. In the next
post, I will be profiling the running time of ProcessQueue against normal Process in
an application.